Last week, as you may remember, I lost my voice (yet again) and produced one segment of the show with an AI-generated voice. I promised to tell you how I did it this week.
Ask ChatGPT
In 2023 I used ElevenLabs.io to produce my voice, but I thought I’d ask ChatGPT what all the cool kids were using this year. I recently started ponying up the $20/month so I could get access to ChatGPT 4o, and in particular to the voice conversation version of ChatGPT. That part wasn’t much use to me though since I’d lost my voice.
My initial query to ChatGPT on the topic was:
I need an AI to read some material in my voice. I have hours of recordings of myself that I can use to train it. Which services would you recommend and what would the cost associated with each option be?
ChatGPT responded with 5 services to consider, along with a section on “how it works” and a cost summary for each. I gave it a little more information based on my use case:
I need this for one-time use, and it will be around 2000 words.
ChatGPT gave me four options, some of which were included in the first set, but gave me a better description of how each could possibly meet my needs. The top two by their description were Resemble AI and Play.ht.
For a one-time use case involving around 2,000 words, you’re likely better off using a service that charges based on output rather than a subscription model. Here are some good options for one-off projects:
- Resemble AI
- How it works: Offers the ability to create a custom voice and pay only for what you generate.
- Cost for one-time use: You can pay for output usage rather than a monthly subscription. Pricing typically starts at around $0.006 per second of generated audio.
- For 2,000 words, which would be about 15 minutes of speech, expect to pay roughly $3-5.
- Best for: High-quality, short-term use.
- Play.ht
- How it works: You can clone your voice and only pay for the audio you generate, rather than subscribing to a plan.
- Cost for one-time use: You can buy credits for short-term needs. Prices start at around $5 for basic audio output, depending on the number of words.
- Best for: Simple, straightforward TTS with your custom voice.
Resemble AI
I started with Resemble AI. Resemble has several pricing plans, the lowest of which is called Creator and costs $29/month, but you can get the first month for $1. That sounded like a good deal just to test it out, so I ordered a subscription and made a reminder to cancel before the first $29 payment came due.

It turns out the Creator plan has some limitations and I’ll explain how these eliminated Resemble for my needs. You get 10,000 seconds of created voice. You get 5 rapid voice clones, and 1 professional voice clone.
The first hurdle with Resemble AI was that I had to record a disclaimer in my own voice that I understood the terms of using it. Remember the problem I had was that I’d lost my voice, right? I managed to croak out the recording, as painful as it was and then I was able to upload some audio of my normal voice to train the service. It was irritating once, but every time I tried to train it again I had to make that audio recording.

While the service says that I should have gotten one professional voice clone with ~98% accuracy, it says that I’ve already used mine up. I don’t remember ever being offered the professional one, but it shows I have one with the status of “pending” so I can’t use it. Rapid Voice Clone said it was 75% voice clone accuracy but I’ll let you be the judge of that when you hear the recording it created for me.
The next task was to upload a voice recording. You can upload a wav or mp3 file and the file size limit is 25MB. I clipped a story from a recent episode of the NosillaCast down to 2 minutes and uploaded it to Resemble AI. After it uploaded and analyzed the audio clip, it asked me to choose the use case for the voice. I could choose from social media, video games, ads, e-learning, corporate videos, voice assistant, dubbing, or podcasts. Obviously, I chose podcasts.
Next, I was asked to select the tone of voice. This was a little harder. My options were emotion, intense, whisper, accented, slow, conversational, explainer, or character. I’m usually explaining things in my podcast so that seemed a good choice. I presumed that I would be able to adjust those based on what I heard, but nope, that voice is locked in with those settings after you create it.
Now I needed to give Resemble AI the script to read. While I had a blog post at the ready, it was filled with Markdown formatting that had to be removed and references to images. It didn’t take me too long to clean it up.
I copied the text, and plopped it into the text box on Resemble AI … and it yelled at me. Turns out it can only do 3000 characters at a time, and this article was 13,709 characters long. I would have to chop it up.

When it was done, I had to say I was pretty disappointed in the results. Not only did it not sound like me, but it actually sounded like it was changing gender between sentences. I’ll let you have a listen:
Audio PlayerSee what I mean? Totally unusable.
At this point, I gave up and used the second service, Play.ht to create the voice you heard last week. I needed to get the show up that same day so I didn’t have a lot of time to experiment with Resemble AI. I’ll explain how Play.ht worked in a minute but I decided this week to go back and see if I could figure out how to get that darned professional clone to work. I paid a whole dollar to test this service, and if I pan it based on the (frankly terrible) quick voice, I haven’t done a good review for you. So before we get to Play.ht, let’s finish out the Resemble AI story.
Remember I said that Resemble AI said I’d used up my professional voice clone and that it said it was in “pending” status? I know for a fact that I never used the professional clone. But when I went back in, I noticed the option to delete the clone. Then I went through the very different steps to create a professional clone. The biggest difference was that they require a full 15 minutes of audio to do the pro voice. I had to go find an episode of the NosillaCast where I didn’t have listener contributions and then slice and dice it to remove the bumper music to get 15 minutes of me.

I uploaded the 15-minute wav file, and after about 5 minutes it came back with an error telling me to start over. Again I recorded my consent and told it to upload the 15-minute file. Oddly it came back almost instantly telling me it was done. And it’s in pending status again. The next morning as I was doing my daily cleanup of my spam folder because Apple is no longer capable of discerning accurately replies to emails I’ve initiated and downright spam, I discovered that Resemble AI had an issue with my upload.
The error was that I had uploaded a WAV file as directed, but that it was improperly encoded. I have little control over the way my software encodes WAV files, so encoded it again but this time as MP3, because they say that both MP3 and WAV are supported for upload.

But they sent me another failure notice telling me that MP3 is not supported, that it has to be WAV. Seriously, these two banners, one saying MP3 is supported and one saying it’s not supported on are the same page.

I opened the MP3 file In Rogue Amoeba’s Fission and then exported as a WAV file so at least a different piece of software was encoding it, and I still got an error from Resemble. This time they didn’t even bother to tell me what was wrong.
There is an issue with the dataset you uploaded. Please fix the issue and re-upload the dataset. Issue: An internal error occurred. Please contact support.
I tried the same file again and this time it accepted it, but wouldn’t let me create a project with it. I entirely deleted the professional voice, and tried a third time, and finally, it said I had a professional synthesized voice I could use.
Now remember they only let you synthesize 3000 characters at a time, so I pasted in the first 2887 characters of the script I wanted Resemble AI to read for me. I waited while the little spinner showed me it was doing some work. And waited. And then took a nap. And then played on TikTok. And it was still spinning. I refreshed the screen finally and it had finished.
And do you know what it said? Yeah, for that professional voice, it’s actually a 2000-character limit, not 3000. Sigh. At this point, I was like a dog with a bone – I was going to beat this thing into submission! I’m glad I kept at it because when I finally got 350 words or so in my own voice with Resemble, it was pretty amazing. I think it captures my voice spot on and is less flat than what you heard last year. It matches my intonation better. It did make some mistakes here and there, for example, you’ll hear some words cut off. It would take a bit of massaging of the text to get it to do everything properly. Ok, enough build-up, let’s listen to Resemble AIs professional voice:
Audio PlayerJust for comparison, here’s how Play.ht performed the same sentences:
Audio PlayerBefore we leave Resemble and go on to Play.ht, remember that to do the whole script I would have to repeat the last (successful) part of the process 7 more times to get the whole article recorded and then stitch them all together. There wasn’t an easy way to regenerate each section so I’m not really sure whether I’d be able to fix all of the errors it made.
Play.ht
Let’s talk about Play.ht now, which as you’ve learned, is the service I ended up using for last week’s show. The bad news was that they didn’t have an inexpensive one-month trial like Resemble. Play.ht has several pricing plans, and they look pretty good at first until you realize that the prices are shown monthly but billed annually. For example, their Unlimited plan is only $29/month but you have to buy a year of it for $348. If you toggle it to show the month-to-month price, it’s $99 for that unlimited plan.
At the other end there’s a free plan, but it’s limited to 12,500 characters and my script was longer than that. The middle tier is called Creator, and the month-to-month price was $39. For that price I could get 250,000 characters in the month, and 10 instant voice clones. I also noticed that only with the paid plans do you get “attribution-free use”. I’m wondering whether there’s actually a voiceover on the free plan, kind of like a watermark on an image.

I mentioned the Creator plan says 250,000 characters per month but they don’t actually calculate it that way. Every time you regenerate a voice clip, you can see a countdown on the number of seconds you have left in your plan. If you hover over the “i” next to 250,000 characters per month it tells you that’s approximately 6 hours. I bring this up because as I was working with Play.ht I was watching the number of seconds count down and I didn’t have any idea where I’d started!
Play.ht doesn’t play well with Safari – the play button wouldn’t, well, play the audio. I switched over to Microsoft Edge, which is a Chromium browser and it started to function properly.
While Play.ht allowed me to import my entire script, when it generated the audio, it did it in a whole slew of short paragraphs, maybe 3 sentences at most. I had to tell it to use my voice, not one of the canned voices they offer.

For each paragraph, there were several controls. I could change the language (which of course I played with but didn’t need.) The initial generation of my voice sounded a bit slow. Above each paragraph is a little timer symbol where you can drag a slider to change the speed. Unfortunately, it doesn’t speed up the individual clip, you have to drag the slider, hit regenerate, wait around 30 seconds or more, and listen again to see if you like it. Every time I hit regenerate, I watched those seconds of credit tick down and get anxious!
Each time you regenerate, next to the given paragraph, you start to see a list of all the regenerated clips. You can delete them or download them or leave them be till the end.
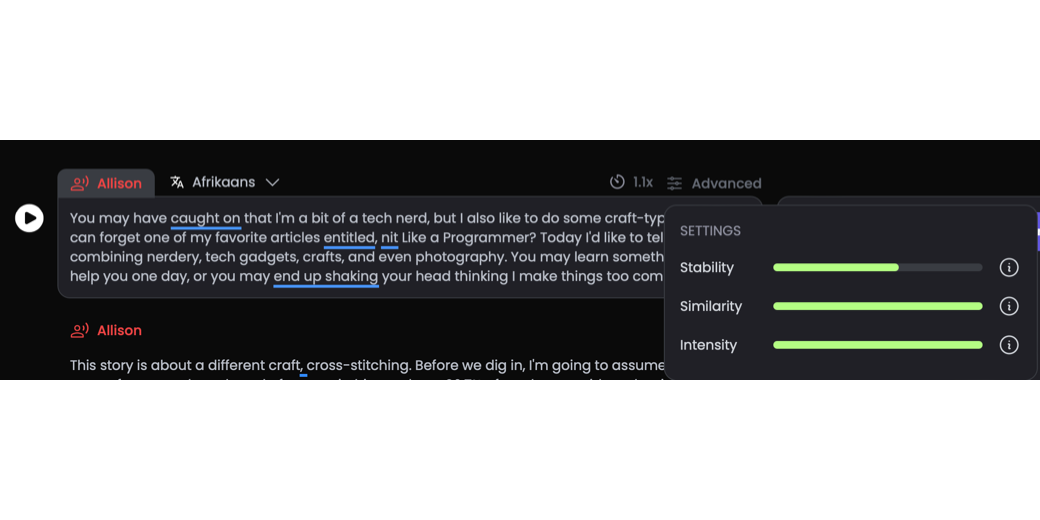
You can also change advanced settings on each clip. The settings sliders are stability, similarity, and intensity. Here’s the help text for each of these settings:
- Stability: Move the slider to the left to create a flatter, more neutral performance. Move it to the right to add expressiveness and variance.
- I sure didn’t want a flat voice, but I found if I moved it too far to the right it was too excitable. After a few trials (watching those seconds count down and getting bored waiting for it to regenerate), I chose 1.20 on a scale of .10 to 2.00
- Similarity: Move the slider to the left to reduce how unique your chosen voice will be compared to other voices. Move it to the right to maximize its individuality.
- Ok, seriously, why would anyone not want it as similar as possible? I cranked this one all the way up.
- Intensity: Language intensity: move it to the right to make the voice follow the selected language accent and style better.
- Same assessment here – I slid the intensity to the max setting

You would think this was something I could decide on just once, and then apply to all of the paragraphs, but you’d be wrong. I had to adjust those three sliders (and the speed) for every single one of the paragraphs, hit regenerate for the given paragraph, wait a minute and watch those seconds count down. Every. Single. Paragraph. I looked for some instructions on how to do this more efficiently but I was unable to find any documentation to follow.
I think this is the kind of tool that a professional would use (maybe one paid by the hour) where tweaking every single paragraph just slightly to get the perfect effect would bring the client joy. But for me just trying to get the podcast out where it sounded pretty close to my voice, it was sheer tedium.

After working my way through a few of the paragraphs, I realized that I actually needed to listen to each one because a few of them had big mistakes. Evidently the word “knit” is foreign to this AI tool, because it insisted on pronouncing it “kit”. I took the “k” out of the word, hit regenerate, waited for it, watched the seconds of credit disappear, and then it said “knit” properly. Play.ht didn’t have much trouble pronouncing things correctly with far fewer errors than Resemble AI. For the errors it did make, I found workarounds by rewording things.
I explained in the article about cross stitching that I keep the thread in little baggies, but Play.ht was convinced that word was “badges”, not “baggies”. After regenerating a couple of times I thought maybe it needed more context, so I made it “ziplock baggies” and then it pronounced the word correctly. However, when I said that some people use little cards that they wind the thread around, Play.ht insisted on pronouncing it wind – like air blowing, not turning something. For the life of me, I couldn’t figure out a different way to spell that one or put it into context!
Making these speed, stability, similarity, and intensity corrections and listening to the clips for correctness, I started to lose my place on which ones I had completed. I had to create a spreadsheet to track my progress!
The other thing that was interesting in a super annoying way is that sometimes the audio generated by Play.ht was completely corrupted. This probably happened every tenth regeneration or so. Here’s what I mean by corrupted.
Audio PlayerI couldn’t very well use that audio, and yes, the countdown of seconds continued even with the broken audio files.
While the process was tedious and time consuming, Play.ht gave me a lot more control on how the voice sounded on a paragraph-by-paragraph basis. Unlike Resemble where I had to use a text editor that would count characters for me and chop up my script into seven pieces by hand, Play.ht used my paragraphs to create the audio for each one.
When I was done tailoring each paragraph and ensuring it didn’t have any avoidable mistakes, I did not have to download every paragraph separately and reassemble them into one audio file. Play.ht has an Export button to save each paragraph separately or as a single audio file.
Bottom Line
The bottom line is that it took me a good couple of hours working with Play.ht to get what I would call a passable representation of my voice to carry you over until I got my voice back. $39 for this one effort doesn’t seem like too big of a price to pay, but it was quite a bit more than ChatGPT suggested. While I enjoy learning a new tool, I found the process of regenerating, waiting, correcting, regenerating, waiting, dragging sliders, regenerating sliders, and waiting to be quite tedious. Maybe I just don’t have the temperament for this level of detail work.
I think Resemble AI did a better job of representing my voice, and the intonation was better. But it did make a lot of mistakes that I’m not entirely sure how I would correct, like cutting off the ends of words. The poor explanations of what kind of audio files Resemble will accept and how many characters you can import as a script was annoying and needs to be fixed. Once I knew what they really wanted (not what they said), it was easy enough to work around it. The entry price of a dollar was totally worth it though.
I hope it’s at least a year before I get to tell you again how I created a synthetic voice to replace my own because of the inevitable laryngitis I will suffer.